Matching HS Codes in 2024: Traversing the Customs Space
A Software Engineer passionate about public good projects and making technology to serve society en masse.
HS (Harmonised System) Codes help classify customs authorities and businesses around the world to ensure appropriate import/export control. This system recursively classifies a product into finer granularity of categories.
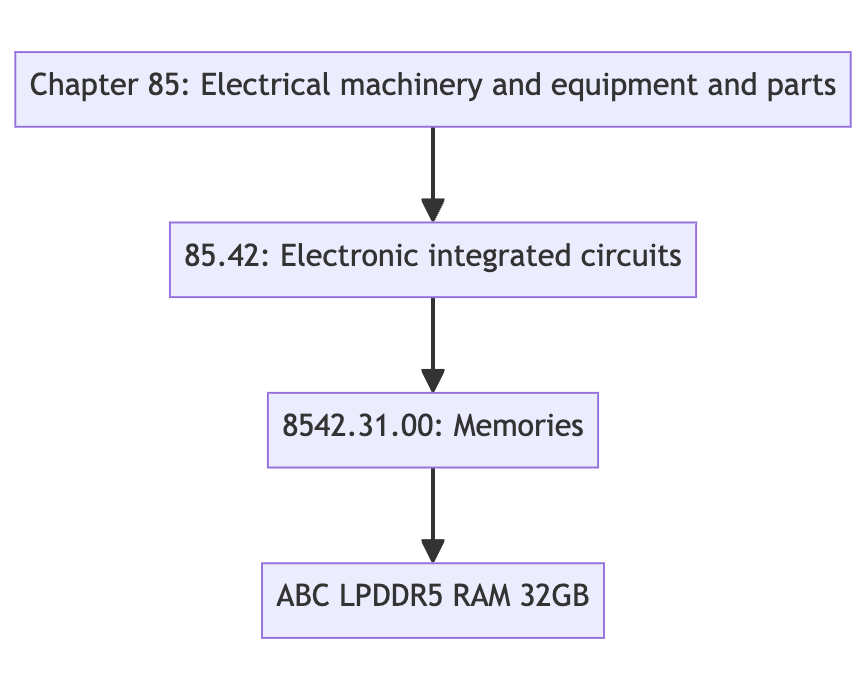
Figure 1: A simple exercise of coding a RAM module.
Could we do this differently with the linguistic tools like LLMs in 2024? This blog examines different approaches towards classification.
Methodology of Classification
Assigning a HS Code is done hierarchically.
Starting off from Chapters, to Sections to further granularities. If we consider this as a search problem, the search domain keeps shrinking as we continue the “process of selection”. i.e., as soon as we classify a product to be an electrical component, we don’t need to keep Wines in the search space.
A graph could be a great solution to this problem!
Resources at our Disposal
We are focusing on classifying according to the definitions set by Singapore Customs.
Constructing a Graph
STCCED, as the name suggests, contains the hierarchical classification of traded goods. It is a PDF file, and the text is divided into Sections, Chapters and “Subchapters”.
Step 1: ⬇️ Download the STCCED 2022 PDF, use PyPDF2 to extract the text content.
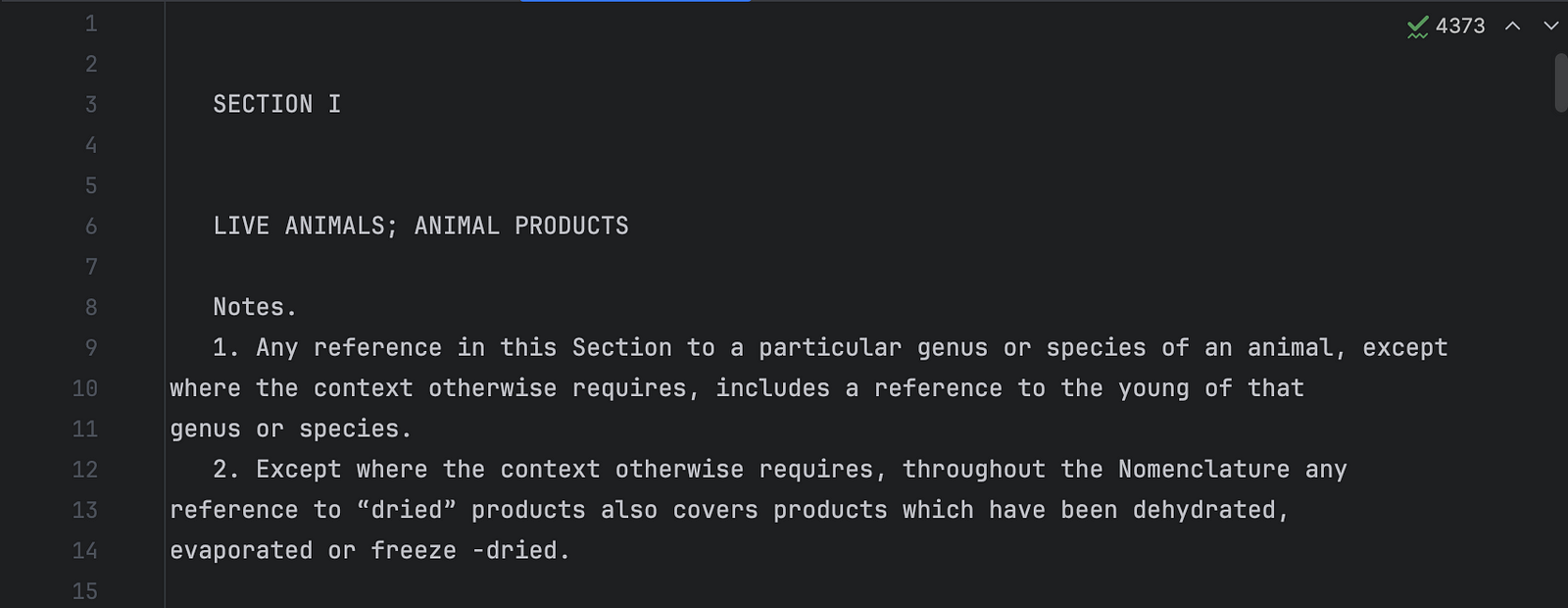
Step 1: Raw text content of STCCED
Step 2: ✂️ Split the text content recursively, into Sections, Chapters and “Subchapters”.
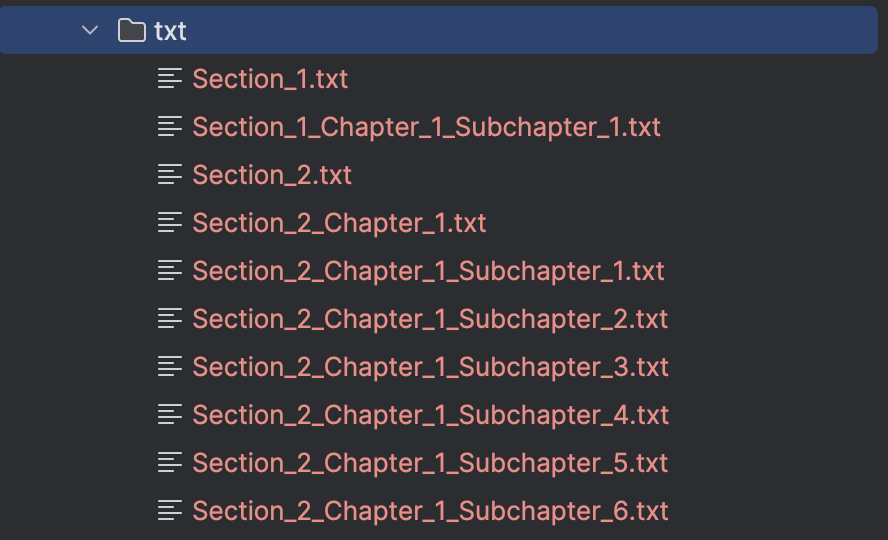
Step 2: The recursively split STCCED!
Step 3: Convert all the subchapters into GraphViz dot files. (Compact representation of parent-child relationships). I used gpt-4 to read the sections and construct these subgraphs.
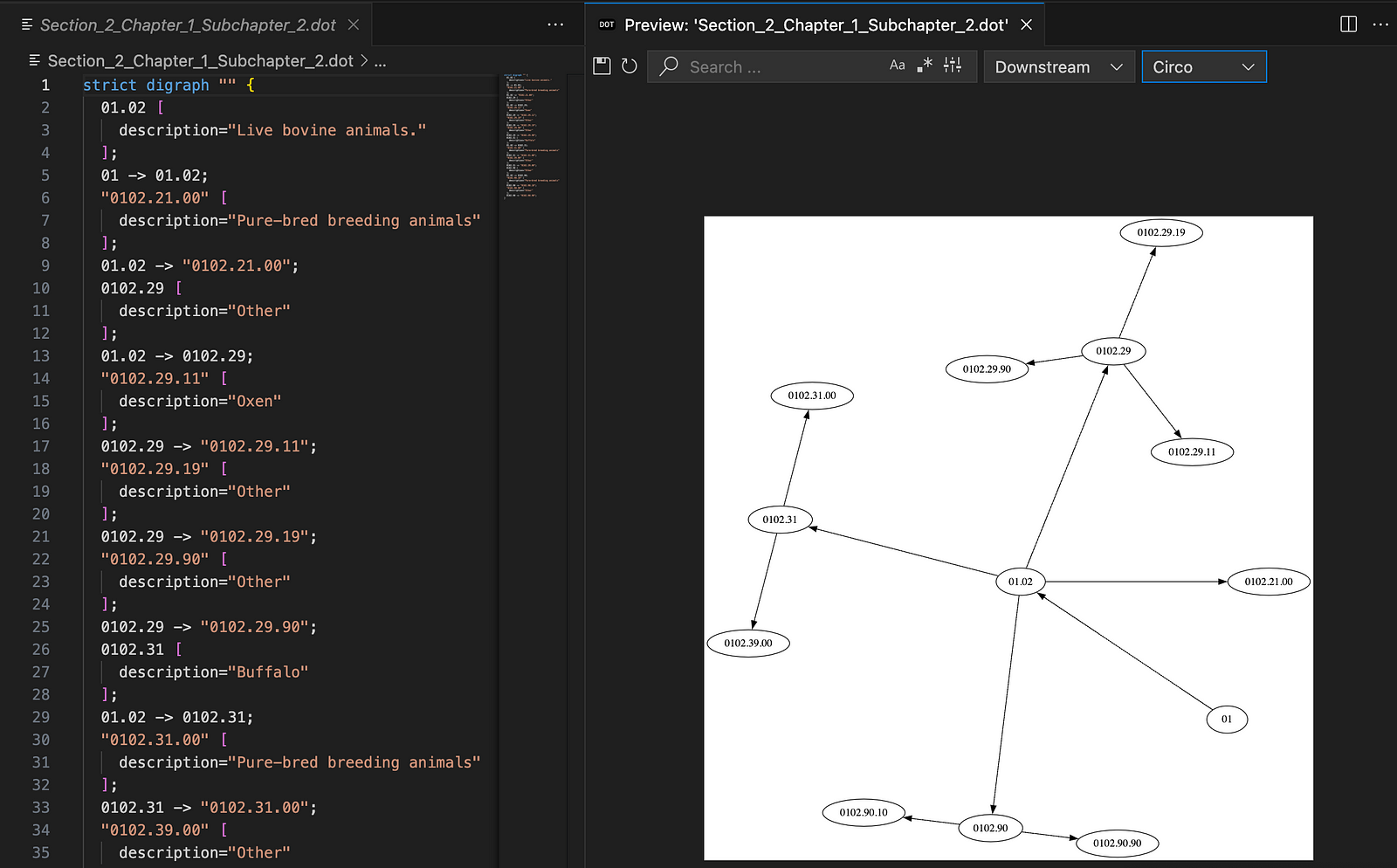
Super-interesting prompt that converted chapter text into GraphViz
Step 4: Merge the subgraphs hierarchically. The result, is a Graph of 13K+ Nodes, neatly organised!

Zooming into the STCCED 2022 Graph!
Building a Hierarchical Search
For each granularity level (Section, Chapter, Subchapter, Dash and Double Dash), I sent requests to gpt-4 directly with a list of the child nodes. Perhaps this illustration will be of assistance!

Illustration of traversing root -> Section -> Chapter…
Thus, progressive granularity would shrink the total search space down.
Giving it some LLM and Streamlit
For the first build, I used openai directly and got streamlit to create the user-interface.
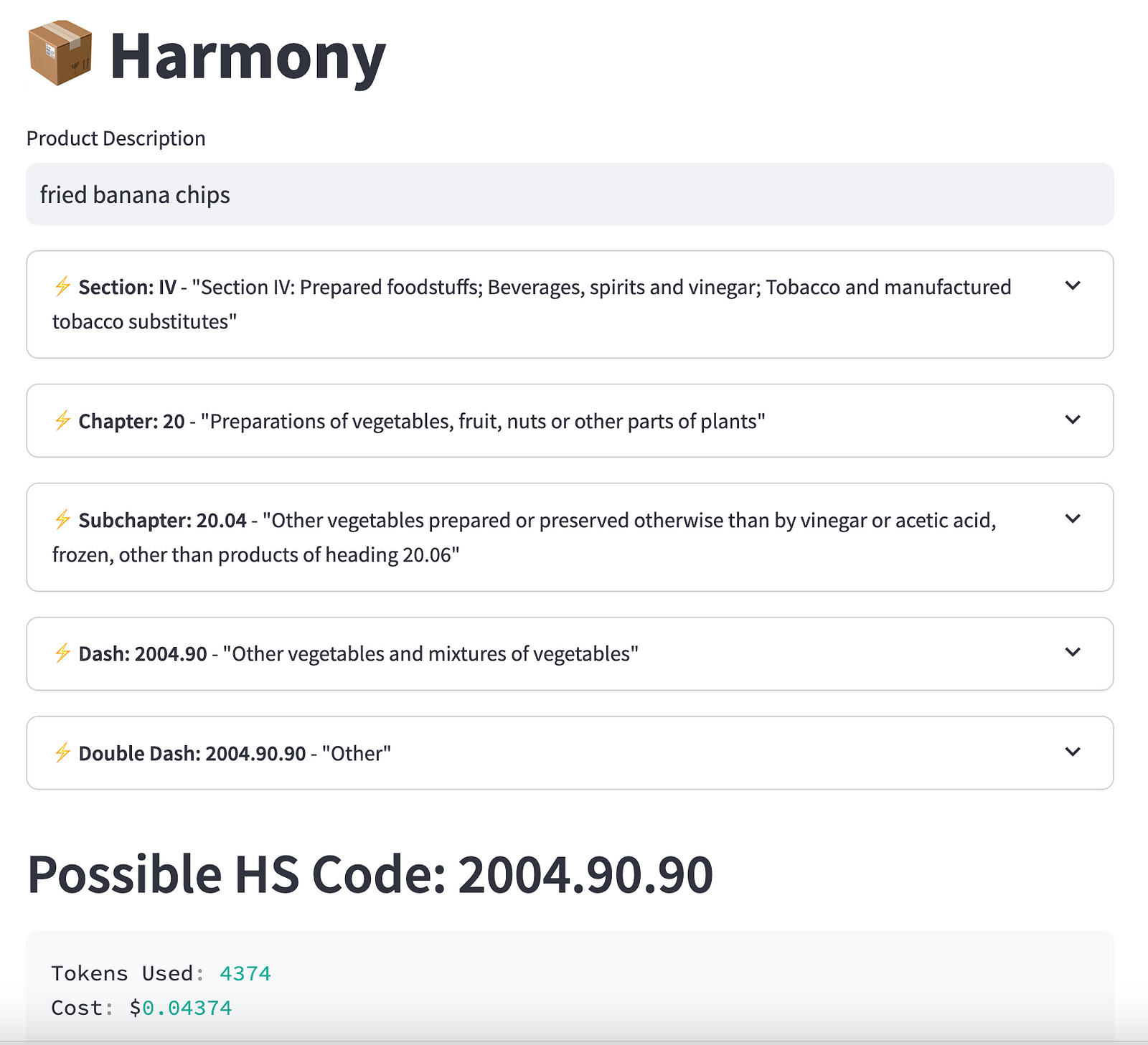
Try it now on Streamlit:
Demo: 🌏 https://harmony-ai.streamlit.app/
GitHub: 🔗 https://github.com/aniruddha-adhikary/harmony
Limitations and Future Work
The current implementation does not go backwards to course-correct. Thus it continues on with a bad classification in a higher granularity.
More tokens may be saved by combining vector search along-side graphs for nodes with larger number of children.